1リポジトリに複数go.modがある場合どうやって各モジュールに異なるバージョンを付与するか
[追記]
公式ドキュメントに解説が書いてあったので英語読める人はこちらを読んでください。
前置き
1つのGitHubのリポジトリにgo.modが1つある場合、そのモジュールのバージョン = gitのタグになる。
gitのタグでv1.0.0というタグをつければ、モジュールのバージョンもv1.0.0になる。
go-libというリポジトリであれば、下記コマンドでバージョンを指定してモジュールを取得できる。
go get github.com/takurooo/go-lib@v1.0.0
では複数のgo.modが1つのリポジトリにある場合はどうすればいいのか。
やり方
gitのタグ名にモジュールのパスも付ければOK。
以下のようなディレクトリ構造のgo-multi-versionというリポジトリがあったとする。
.
├── module1
│ ├── go.mod
│ └── module1.go
└── module2
├── go.mod
└── module2.go
module1にv0.0.1を付けたい場合はタグ名をmodule1/v0.0.1にする。
module2にv1.0.0を付けたい場合はタグ名をmodule2/v1.0.0にする。
タグ名にモジュールまでのパスを含めることで各モジュールごとにバージョンを付与することができる。
go getするときは以下のように実行する。
go get github.com/takurooo/go-multi-version/module1@v0.0.1 go get github.com/takurooo/go-multi-version/module2@v1.0.0
以下のようにバージョン指定するとエラーになる。
go get github.com/takurooo/go-multi-version/module1@v1.0.0 go get github.com/takurooo/go-multi-version/module2@v0.0.1
ちなみにAWS SDKは1つのリポジトリに複数のgo.modを持っている。
実験したリポジトリ
CodeBuildのWebhookイベントでPULL_REQUEST_MERGEDを指定するとPRのブランチで処理が開始する
- 前置き
- 本題
- PULL_REQUEST_MERGEDでCodeBuildを起動するときPullRequestのブランチでCodeBuildが起動してしまう
- GitHubのイベントでCodeBuildを起動するときマージされたmainブランチ上で処理をしたい場合どうすればいいか
前置き
GitHubのWebhookを使うとPullRequestがマージされたときにAWSのCodeBuildを起動できる。
CodeBuild側でどんなイベントで起動するのかを指定できる。
下記イベントを選択できる
- PUSH
- PULL_REQUEST_CREATED
- PULL_REQUEST_UPDATED
- PULL_REQUEST_REOPENED
- PULL_REQUEST_MERGED
設定画面はこんな感じ

ちなみにGitHubのWebhookにはPULL_REQUEST_MERGEDというイベントは存在しない。これはGitHubから通知される情報を組み合わせてCodeBuild側がPullRequestがマージされたと判断している。
GitHubのイベントとCodeBuildのイベントの対応表は下記リンクに書いてある。
GitHubから通知される情報は下記リンクに書いてある。
GitHubが通知したイベントの履歴はリポジトリのSettings->Webhooksから見れる。
本題
PULL_REQUEST_MERGEDでCodeBuildを起動するときPullRequestのブランチでCodeBuildが起動してしまう
GitHubのイベントでCodeBuildを起動するとき、CodeBuildには起動時に自動でGitHub上のコードがダウンロードされる。
GitHubのPullRequestがマージされたらマージされたmainブランチをCodeBuildで処理したい場合、PULL_REQUEST_MERGEDを選択したくなる。しかしPULL_REQUEST_MERGEDでCodeBuildを起動するとPullRequestのブランチでCodeBuildが起動する。
PULL_REQUEST_MERGEDで起動したCodeBuildのビルド履歴。ソースバージョンがpr/10になっている。これはNo10のPRのソースであることを意味している。

このときマージしたPRはこれ
AWSのユーザーガイドにもちゃんと書いてある。
Webhook プルリクエストイベントによりトリガーされた GitHub または GitHub Enterprise Server ビルドの場合、pr/pull-request-number です。
GitHubのイベントでCodeBuildを起動するときマージされたmainブランチ上で処理をしたい場合どうすればいいか
1. CodeBuildのbuildspecでgit checkout mainを実行する
CodeBuildの起動イベントはPULL_REQUEST_MERGEDを指定する。PullRequstのブランチで処理が開始するが、buildspecのどこかのフェーズにgit checkout mainを書いてmainブランチに切り替える。
このとき切り替わったmainブランチはPullRequstがマージされた最新のmainブランチになっている。
2. CodeBuildの起動イベントにPUSHを指定する
CodeBuildの起動イベントでPULL_REQUEST_MERGEDではなくPUSHを指定する。
GitHubでPullRequstを作ってからマージされるまでにGitHubからCodeBuildに下記のイベントが通知される。
pull_request.openedpull_request.closedpush
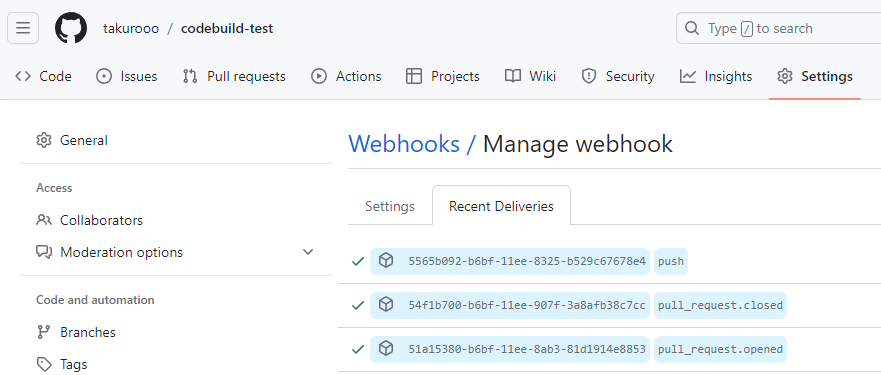
CodeBuildのPULL_REQUEST_MERGEDはpull_request.closedに対応している。PUSHを指定するとpushのタイミングでCodeBuildが起動する。このときCodeBuild上にダウンロードされるコードはPullRequstがマージされた最新のmainブランチになっている。
この設定ではmainブランチに直接プッシュしたときにもCodeBuildが起動するので、PullRequstがマージされたときだけCodeBuildを起動したい場合はmainブランチへの直接のプッシュを禁止する設定をしたほうがよさそう。
Go go.modのモジュール名がGitHubのリポジトリと一致しないものをimportしようとするとどうなるのか
importできません。
目次
呼び出される側のモジュールを作る
module helloworld go 1.21.4
helloworld.goを作成する。
package helloworld import "fmt" func HelloWorld() { fmt.Println("Hello World!") }
呼び出す側を作る
- go-sampleというフォルダを作成して
go mod init sampleを実行する。 main.goを作成する。ここでさっきのgo-helloworldをインポートする。
package main import "github.com/takurooo/go-helloworld" func main() { helloworld.HelloWorld() }
go mod tidyを実行するとgithub.com/takurooo/go-helloworldをdownloadするがmoduleの宣言がgithub.com/takurooo/go-helloworldになっていないと表示される。
go: finding module for package github.com/takurooo/go-helloworld
go: downloading github.com/takurooo/go-helloworld v0.0.0-20240104074603-37cc24b9797d
go: found github.com/takurooo/go-helloworld in github.com/takurooo/go-helloworld v0.0.0-20240104074603-37cc24b9797d
go: sample imports
github.com/takurooo/go-helloworld: github.com/takurooo/go-helloworld@v0.0.0-20240104074603-37cc24b9797d: parsing go.mod:
module declares its path as: helloworld
but was required as: github.com/takurooo/go-helloworld
go run main.goを実行してもmoduleがなくてエラーになる。
main.go:3:8: no required module provides package github.com/takurooo/go-helloworld; to add it:
go get github.com/takurooo/go-helloworld
まとめ
Pythonのパッケージ管理ツールRyeに関するメモ
Ryeを触ってみたので忘れないようにメモしておく。
色々触ったときのリポジトリ
目次
- 目次
- インストール方法
- プロジェクトの作成
- 仮想環境の構築と依存パッケージのインストール
- 仮想環境の有効化
- shims下のpythonコマンドについて(~/.rye/shims/にあるpythonとpython3)
- グローバルなツール
- その他
- 参考リンク
インストール方法
ここに書いてある。 rye-up.com
Linuxなら
# インストール $ curl -sSf https://rye-up.com/get | bash # 環境パス追加 $ echo 'source "$HOME/.rye/env"' >> ~/.bashrc # アップデート rye self update # アンインストール rye self uninstall
envはシェルスクリプトになっていて、PATHに$HOME/.rye/shimsがなければexport PATH="$HOME/.rye/shims:$PATHを実行してくれる。
$ cat ~/.rye/env # rye shell setup case ":${PATH}:" in *:"$HOME/.rye/shims":*) ;; *) export PATH="$HOME/.rye/shims:$PATH" ;; esac
なので、$HOME/.rye/shims:$PATHに実行ファイルがあるそう。
$ ls ~/.rye/shims/
python python3 rye
これでryeコマンドが使える。
pythonとpython3がshims下にある理由は後述
プロジェクトの作成
# rye_sampleというプロジェクトを作る
$ rye init rye_sample
$ tree rye_sample/
rye_sample/
├── README.md
├── pyproject.toml
└── src
└── rye_sample
└── __init__.py
この他に隠しファイルとして.gitや.gitignore、.python-versionも生成されている。
重要なのはpyproject.tomlと.python-version。
pyproject.tomlはPythonのパッケージ情報やRyeのコンフィグレーションが書かれている。
.python-versionは使用するpythonのバージョンが書いてある。
$ cat .python-version cpython-x86_64-linux@3.12.0
この時点では3.12のpythonはインストールされていない。
仮想環境の構築と依存パッケージのインストール
# flaskを依存パッケージに追加 $ rye add flask # blackをdevの依存パッケージに追加 $ rye add --dev black # 仮想環境の構築 $ rye sync # devの依存パッケージを含みたくない場合 $ rye sync --no-dev # パッケージを削除した場合 $ rye remove flask $ rye sync
rye add <package-name>で依存パッケージの追加をできるが、このコマンドはpyproject.tomlに依存パッケージの記述を追加するだけ。
rye syncで下記処理が実行される。
.python-versionに書かれているPythonのインストール- 仮想環境の``.venv"フォルダを生成 or 更新
- ロックファイルの生成 or 更新(
requirements.lock/requirements-dev.lock)
仮想環境の有効化
# 仮想環境有効化 $ . .venv/bin/activate # 仮想環境無効化 $ deactivate
仮想環境を有効化しなくても、プロジェクト内でpythonと実行すると仮想環境内のPythonを参照してくれる。
shims下のpythonコマンドについて(~/.rye/shims/にあるpythonとpython3)
Ryeをインストール後、~/.rye/shims/がPATHに追加される。
ここにpythonとpython3がいる。
よってpython or python3と実行するとシステムにインストールされているpythonではなく、shims下のpythonが実行される。
shims下のpythonコマンドがどう振る舞うかは下記ドキュメントに書かれている。
Inside a Rye managed project they resolve to the Python interpreter of the virtualenv. This means that even if you do not enable the virtualenv, you can just run python in a shell, and it will automatically operate in the right environment.
Ryeのプロジェクト内の場合は、仮想環境を有効化しなくても仮想環境のPythonを起動してくれる。
Outside a Rye managed project it typically resolves to your system Python, though you can also opt to have it resolve to a Rye managed Python installation for you. This is done so that it's not disruptive to your existing workflows which might depend on the System python installation.
Ryeのプロジェクト外の場合は、システムにインストールされているPythonを起動してくれる。 ただし、下記コマンドを実行するとRyeがインストールしたPythonに切り替えることもできるとのこと。
$ rye config --set-bool behavior.global-python=true # 上記コマンドでconfig.tomlが編集される # rye config --show-path でコンフィグの場所が分かる $ cat ~/.rye/config.toml [behavior] global-python = true
違うバージョンのPythonを使いたい場合はインストールが必要
# Pythonをインストール $ rye fetch 3.9 # こっちのコマンドでもインストール可能 $ rye toolchain fetch 3.9 # インストール済みPythonを確認 $ rye toolchain list cpython@3.12.0 (/home/hoge/.rye/py/cpython@3.12.0/install/bin/python3) cpython@3.9.18 (/home/hoge/.rye/py/cpython@3.9.18/install/bin/python3) # インストール済みの特定のバージョンのPythonを使う # このコマンドはRyeのプロジェクト外でしか使えない $ python +3.9 sample.py # インストール済みPythonを削除 $ rye toolchain remove 3.9.18
グローバルなツール
blackはプロジェクトごとではなく、どこでも共通で使えるようにしたい場合、global toolとしてインストールできる。
# global toolとしてblackをインストール $ rye install black # global toolとしてインストールされてもののリストを表示 $ rye tools list black # 削除 $ rye uninstall black
その他
pyproject.tomlの中身の意味はここを見る
ビルドとパブリッシュについてはここを見る
グローバルなコンフィグファイル(config.tomlとか)についてはここを見る
参考リンク
ドキュメント
rye-up.com
デモ動画
www.youtube.com
Lambdaがエラーレベルのログを出力したらTeamsにメッセージを通知する
Lambdaがエラーレベルのログを出力したらTeamsに通知する仕組みを作ってみたので関連情報をまとめておく。
目次
構成図

ポイント解説
エラーレベルのログ検出方法
Lambdaが出力したログ(CloudWatch Logs)が特定の条件にマッチしたら、CloudWatch Metricsにメトリクスを送信する仕組み(メトリクスフィルター)があるので、エラーレベルのログの検出はこれを使う。
フィルターを使用したログイベントからのメトリクスの作成 - Amazon CloudWatch Logs
LambdaのログをJSON形式で出力しておけば、「特定のキーの文字列が~だったら」という条件でメトリクスを送信できる。下記のようにlevelというキーを出力しておけば、「levelがERRORだったら」メトリクスとして出力が可能になる。
{ "level" : "ERROR", "message" : "xxxxxxxxx" }
メトリクスフィルターの条件は
{ $.level = "ERROR" }
のように書けばOK。
フィルターとパターンの構文 - Amazon CloudWatch Logs
Teamsにメッセージを送信する方法
まずはTeams側でWebHookを作成して、TeamsのWebhookのURLを取得する。
TeamsのWebhookの作り方
受信 Webhook を作成する - Teams | Microsoft Learn
learn.microsoft.com
SNSのメッセージをTeamsに送信する方法はここにサンプルコードがある。
repost.aws
Teamsのメッセージ仕様
Teamsにそのまま文字列を送信しても問題ないが、メッセージをカスタマイズしてカード形式で送信することもできる。
ここではコネクタカードとアダプティブカードの2種類のメッセージ形式が紹介されている。
アダプティブカードはメッセージのカスタマイズが柔軟にできる。今回はコネクタカードでもやりたいことはできそうなので、コネクタカードを選択した。
コネクタカードだとこんな感じのカードが作れる。
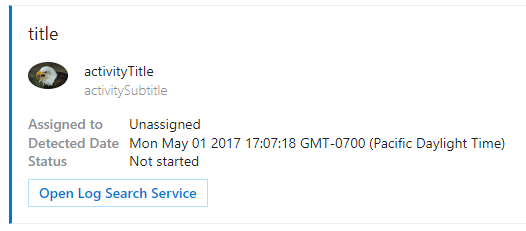
learn.microsoft.com
その他にも色々なカードがある。違いは下記リンクを参照
learn.microsoft.com
コネクタカードの詳細な仕様はこちら
learn.microsoft.com
Playgroundがあるので、仕様を見ながらここでメッセージの形式を整える。
messagecardplayground.azurewebsites.net
今後の改善でやりたいこと
- 今は通知受信後にユーザーがエラーログを手動で検索するようになっているが、出力されたエラーログをプログラムで検索して、Teamsのメッセージに送信したい。エラーログを確認して、さらに詳細な解析が必要であれば、ログ検索サービスを使うイメージ。
- エラーが通知されたらJIRAやRedmineでチケットを作成して調査するのが基本なので、Teamsのメッセージ上でチケット作成ボタンを配置したい。チケットを自動作成するという方法もあるが、同じエラーが大量に発生した場合に困りそうなのでまずは自動化しないほうが良さそう。
Prompt Enginnering Guideを読んで気になったことのメモ
目次
概要
Prompt Enginnering GuideというChatGPTなどのLLMsを使う時に入力するテキスト(プロンプト)を設計するときのガイドを読んだので自分が使えそうだなと思った箇所だけメモしていく。
Prompt Enginnering Guideの日本語訳 www.promptingguide.ai GitHubのリポジトリ github.com
プロンプトエンジニアリングとは
ChatGPTなどを使ってあるタスクを実行するために最適な入力テキスト(プロンプト)を設計するアプローチとのこと。
ChatGPTを使って何かタスクを実行するときに、与えるプロンプトに応じて出力される回答が変化する。このとき自分が望む回答をChatGPTから引き出すには最適なプロンプトを与えてあげる必要がある。Prompt Enginnering Guideには、この最適なプロンプトを構築するヒントが書かれている。
プロンプトの要素
プロンプトに以下の要素が含まれることがあるとのこと。
- 命令:モデルに実行してほしい特定のタスクまたは命令
- 文脈:外部情報や追加の文脈
- 入力データ:入力または質問
- 出力指示子:出力タイプ、形式
これらすべてが常に必要というわけではない。
自分のタスクに合わせてどれとどれを組み合わせてプロンプトを構成するのか考える必要がありそう。
命令や入力データはほとんどのケースで必要になりそう。出力指示子は表形式とかマークダウンで出力したい場合にプロンプトに追加するものだと思う。おそらく「文脈」は回答の精度を高めたいときに検討するものだと思うので、最適な文脈を見つけてプロンプトに組み込むのが一番難易度が高そう。
プロンプトの設計に関する一般的なヒント
ヒントとして下記のようなことが書かれている。
- プロンプト設計は反復的なプロセスである。
- プロンプト設計はシンプルなプロンプトから始める。
- 結果を向上させるために要素や文脈を追加していく。
- 大きなタスクは小さなサブタスクに分解する。
- 指示はプロンプトの最初に配置し、指示と文脈を区切るために「###」のような区切り文字が推奨されている。
### 指示 ### 以下のテキストをスペイン語に翻訳してください。 Text: "hello!"
- プロンプトは詳細で具体的であるほど、結果はよくなる。
- プロンプトに例を与えることは、特定のフォーマットで出力を得るために効果的である。
- 「しないこと」を言わずに、「することを」を言う。
最初から複雑なプロンプト突っ込まないでまずはシンプルなプロンプトから始めていき、出力を見ながらプロンプトを微調整(要素や文脈を追加)していく作業がプロンプトの設計らしい。
「大きなタスクは小さなサブタスクに分解する」というところにもプロンプトの設計の工夫が必要そう。この場合も大きなタスクを投げてみて期待する結果に到達しなさそうだったらタスクを分解してみて依頼する、もしくはその分解自体を依頼するみたいな反復作業が必要なんだろうと思う。
プロンプトの例
プロンプトの使用パターンも載っていた。
- テキスト要約
- 情報抽出
- 質疑応答
- テキスト分類
- 会話
- コード生成
- 推論
このパートでは「こんな感じでLLMs使えますよ」みたいな紹介が書いてある。
面白そうだったのが「会話」で下記のようなプロンプトが書かれていた。
以下はAI研究アシスタントとの会話です。アシスタントのトーンは技術的で科学的です。 人: こんにちは、あなたは誰ですか? AI: ご挨拶!私はAI研究アシスタントです。今日は何をお手伝いできますか? 人: ブラックホールの生成について教えてもらえますか? AI:
このように役割を与えるようなプロンプトをrole promptingと呼ぶらしい。
Techniques
ここでは実際にプロンプトを設計するときの技が紹介されていた。
下記使えそうなものをピックアップした。
Zero-shot prompting
モデルに例を提示しないプロンプト。一番シンプルなやつ。
入力
次のテキストがポジティブかネガティブか判定してください。 テキスト:仕事が楽しい
出力(GPT-3.5)
このテキストはポジティブな表現です。"仕事が楽しい"という文は、仕事に対してポジティブな感情を示しています。
Few-shot prompting
モデルに例を提示するプロンプト。提示した例からモデルがタスクをどうやって実行するか学習してくれる。
入力
今日はだるい この表現はネガティブです。 仕事行きたくない この表現はネガティブです。 今日は華金だ この表現はポジティブです。 仕事が楽しい
出力(GPT-3.5)
この表現はポジティブです。
例を示すだけで特に指示しないでも期待通りの形式で出力してくれた。 ただしfew-shot promptingは推論を含むタスクではうまく機能しないとのこと。推論を含むタスクでは口述する「Chain-of-Thought prompting」と「Zero-shot COT prompting」が有効とのこと。
Chain-of-Thought prompting
中間的な推論ステップを示すプロンプト。
下記例はPrompt Enginnering Guideに掲載されていた例。「奇数を全て加えると...」の部分で推論をどのようにするかのヒントを与えている。
このグループの奇数を合計すると偶数になります。: 17、9、10、12、13、4、2。 A: 奇数を全て加えると(17, 9, 13)39になります。答えはFalseです。 このグループの奇数を合計すると偶数になります。: 15、32、5、13、82、7、1。 A:
GPT-3.5はChain-of-Thought prompting使わずに「このグループの奇数を合計すると偶数になります。: 15、32、5、13、82、7、1。」だけで正解していた。
Zero-shot COT prompting
こちらは「ステップバイステップで考えてみましょう」という文言をプロンプトに追加するアイデア。 下記例はPrompt Enginnering Guideに掲載されていた例。
私は市場に行って10個のリンゴを買いました。隣人に2つ、修理工に2つ渡しました。それから5つのリンゴを買って1つ食べました。残りは何個ですか?
これをGPT-3.5に入力すると間違えた答えを出力した。
最初に10個のリンゴを買いましたが、隣人と修理工に2つずつ渡したので、2つ+2つ=4つのリンゴを渡しました。したがって、最初の10個のリンゴから4つのリンゴが減り、残りは6つのリンゴです。 その後、5つのリンゴを買いましたが、1つを食べたので、残りは5つ-1つ=4つのリンゴがあります。 したがって、最初に10個のリンゴを買い、隣人と修理工に2つずつ渡し、5つのリンゴを買って1つ食べた後、残りは4つのリンゴです。
次に「ステップバイステップで考えてみましょう」という文言をプロンプトに追加したところ見事に正解になった。
入力
私は市場に行って10個のリンゴを買いました。隣人に2つ、修理工に2つ渡しました。それから5つのリンゴを買って1つ食べました。残りは何個ですか? ステップバイステップで考えてみましょう。
出力(GPT-3.5)
最初に市場で10個のリンゴを買いました。 リンゴの数:10 その後、隣人に2つのリンゴを渡しました。 リンゴの数:10 - 2 = 8 修理工にも2つのリンゴを渡しました。 リンゴの数:8 - 2 = 6 その後、5つのリンゴを追加で購入しました。 リンゴの数:6 + 5 = 11 最後に、1つのリンゴを食べました。 リンゴの数:11 - 1 = 10 したがって、残りのリンゴの数は10個です。
ただこのプロンプトを何回か試しているとたまに間違った答えを出すので100%正解させるためにはまだまだ工夫が必要そう。
ちなみにZero-shot COT prompting を使わずにGPT-4に同じプロンプトを入力したところ1発で正解した。
入力
私は市場に行って10個のリンゴを買いました。隣人に2つ、修理工に2つ渡しました。それから5つのリンゴを買って1つ食べました。残りは何個ですか?
出力(GPT-4)
最初に10個のリンゴを買い、隣人に2つ、修理工に2つ渡したので、6個のリンゴが残ります。それから5つのリンゴを追加で購入し、1つ食べました。その結果、6個 + 5個 - 1個 = 10個のリンゴが残ります。
まとめ
個人的には「Chain-of-Thought prompting 」や「Zero-shot COT prompting 」が興味深かった。元のプロンプトでは答えにたどり着けないのに、思考のヒントを与えるだけでそのヒントを駆使して答えにたどり着く様子が面白かった。こういうのを見るとプロンプト設計試験とかも今後出てきそう。
一方でGTP-4ではこれらのテクニックを使用しないでも正解を出力できたところを見るとこういったテクニックもモデルの性能が向上するにつれて徐々に不要なものになっていきそう。そうなればそうなったでまた新しいテクニックがでてくると思うけどどうなんだろう。
Few-shot prompting と Role prompting は回答の精度を上げるとか以外にアプリケーションとして色々使い道がありそうなので、この辺のプロンプト例とか漁ってみると面白いアイデアとか出てきそう。
Video.js入門
目次
- 目次
- Video.js
- シンプルなビデオプレーヤーを作る
- クラスでビデオプレーヤーのレイアウトを設定する
- オプションでビデオプレーヤーの機能を設定する
- ビデオプレーヤーのコールバックを設定する
- ビデオプレーヤーを操作する
Video.js
JavaScriptで簡単に動画のプレーヤー作れるよ。
HLSやMPEG-DASHの再生も簡単にできるよ。
シンプルなビデオプレーヤーを作る

<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Video.js</title> <!-- Video.js CDN --> <link rel="stylesheet" href="https://vjs.zencdn.net/7.4.1/video-js.css"> <script src="https://vjs.zencdn.net/7.4.1/video.js"></script> </head> <body> <video-js id="videoPlayer" width=640 height=480 controls> <source src="https://bitdash-a.akamaihd.net/content/MI201109210084_1/m3u8s/f08e80da-bf1d-4e3d-8899-f0f6155f6efa.m3u8" type="application/x-mpegURL"> </video-js> <script> videojs('videoPlayer'); </script> </body> </html>
コード説明
まずVideo.jsを使用するためにCDNからVideo.jsを読み込む
<head> ・ ・ ・ <!-- Video.js CDN --> <link rel="stylesheet" href="https://vjs.zencdn.net/7.4.1/video-js.css"> <script src="https://vjs.zencdn.net/7.4.1/video.js"></script> </head>
プレーヤー下記部分で定義している。
<body> <video-js id="videoPlayer" width=640 height=480 controls> <source src="https://bitdash-a.akamaihd.net/content/MI201109210084_1/m3u8s/f08e80da-bf1d-4e3d-8899-f0f6155f6efa.m3u8" type="application/x-mpegURL"> </video-js> <script> var player = videojs('videoPlayer'); </script> </body>
<video-js id="videoPlayer" width=640 height=480 controls>ここがプレーヤーの外観を定義している。widthとheightはプレーヤーの幅と高さ、controlsはプレーヤーを操作するボタン(再生開始、停止など)を表示させることを意味している。<source .... >の部分で再生させるビデオを指定している。今回はHLS形式のサンプル動画を指定している。手持ちのMP4ファイルを指定したい場合は、<source src="./Dog.mp4" type="video/mp4">とすればよい。var player = videojs('videoPlayer');はJavaScript側でプレーヤーを制御するためのPlayerオブジェクトを生成している。先ほど設定したプレーヤーのwidthや再生させるビデオなどはこのPlayerオブジェクトを使っても設定できる。
ちなみにPlayerオブジェクトは下記方法でも取得可能
videojs('videoPlayer'); var player = videojs.getPlayer('videoPlayer')
また、videojs.getPlayers()は存在する全てのPlayerオブジェクトを返してくれる。
videojs('videoPlayer'); var player = videojs.getPlayers().videoPlayer
クラスでビデオプレーヤーのレイアウトを設定する
Video.js関連のクラスを使うとプレーヤーのレイアウトを設定することができる。 例えばこんな感じに設定できる。
<video-js id=videoPlayer class="vjs-fluid vjs-big-play-centered" controls>
vjs-fluidはブラウザの大きさに合わせてプレーヤーの大きさが変化するようになる。これを設定している時はwidthやheightの設定は無視される。vjs-big-play-centeredを設定すると、再生開始ボタンが画面中央に表示されるようになる。
結果下記のような画面になる。
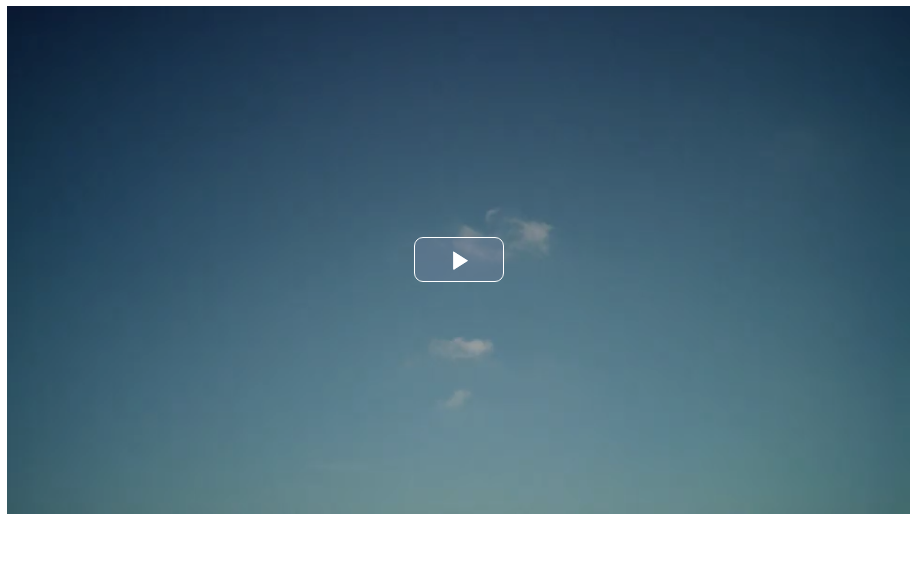
Layoutのチュートリアル
docs.videojs.com
vjs-big-play-centered class
https://docs.videojs.com/docs/guides/setup.html
オプションでビデオプレーヤーの機能を設定する
先に出てきたwidthとheightの他に、プレーヤーには色々なオプションを設定することができる。
オプションはHTML側でも設定できるが、ここではJavaScript側で設定してみる。
var player = videojs('videoPlayer', { autoplay: false, loop: false, controls: true, preload: 'auto', playbackRates: [0.5, 1, 1.5, 2] });
videojs関数の第二引数にプレーヤーのオプションを渡すことができる。
設定できるオプションと各オプションの説明はここで見れる。
https://docs.videojs.com/docs/guides/options.html
今回設定している項目
* autoplay : ビデオ読み込み後、自動で再生するか
* loop : ビデオ終了後、再度自動で最初から再生するか
* controls : 先ほどでてきたプレーヤーをコントロールするボタンを表示するかどうか
* preload : ビデオタグ読み込み後、すぐにビデオを読み込むかどうか
* playbackRates : ビデオ再生速度を切り替えるボタンを表示するかどうか
playbackRatesで4つの再生速度を設定しているのでコントロールパネルには下記のようにボタンが追加される。

ビデオプレーヤーのコールバックを設定する
Video.jsプレーヤーのsetupは非同期に完了する。なので「プレーヤーのsetupが終わった後に何か処理をしたい」という場合はreadyコールバック使うことが推奨されている。
readyコールバックはvideojs関数の第三引数で設定できる。
var player = videojs('videoPlayer', null, function () { console.log("ready"); });
この他にもplayer.ready()やplayer.on()を使ってもコールバックを登録することができる。
player.ready(
function () {
console.log("ready");
}
)
player.on('ready', function (e) { console.log("ready"); } )
ただplayer.onを使う場合はsetupが完了する前にコールバックを設定しなくていけない。Video.jsのsetupが完了した後に、player.onでreadyコールバックを設定してもコールバックが呼ばれることはないので注意が必要。
player.ready()は設定時にsetupが終わっている場合は即時コールバックを呼んでくれる仕様なので、readyコールバックに関してはvideojsの第三引数で設定するかplayer.ready()で設定するのが良さそう。
またplayer.onではready以外のコールバックも設定することができる。
player.on(
['loadstart', 'loadedmetadata', 'loadeddata', 'play', 'playing', 'pause', 'suspend', 'seeking', 'seeked', 'waiting', 'canplay', 'canplaythrough', 'ratechange', 'ended', 'emptied', 'error', 'abort'],
function (event) {
console.log(`Player Event : ${event.type}`);
}
);
ビデオプレーヤーを操作する
Playerオブジェクト経由でプレーヤーの再生や停止などを制御できる。
Video.js Playerオブジェクト仕様 docs.videojs.com
再生するソースを設定する
player.src({ type: "application/x-mpegURL", src: "https://bitdash-a.akamaihd.net/content/MI201109210084_1/m3u8s/f08e80da-bf1d-4e3d-8899-f0f6155f6efa.m3u8" });
ビデオを再生する
player.play();
ビデオを停止する
player.pause();
ビデオをミュートする
player.muted(true);
再生中のビデオの解像度を取得する
console.log(player.videoHeight()); console.log(player.videoWidth());
再生中のビデオの音のボリュームを設定する
player.volume(0.5);
プレーヤーを隠す
player.hide();
プレーヤーを表示する
player.show();