Vue.jsを触ってみたかったので、Chat風のWebSocketクライアントを作ってみた。

目次
作ったもの
Chat部分
Chat部分はこちらのCodepenのコードを使った。 codepen.io
メッセージ表示部分
<section ref="messageArea" class="message-area"> <p v-for="message in messages" class="message" :class="{ 'sent-message': message.from === 'client', 'received-message': message.from === 'server', 'system-message': message.from === 'system' }"> {{ message.date }} <br> {{ message.body }} </p> </section>
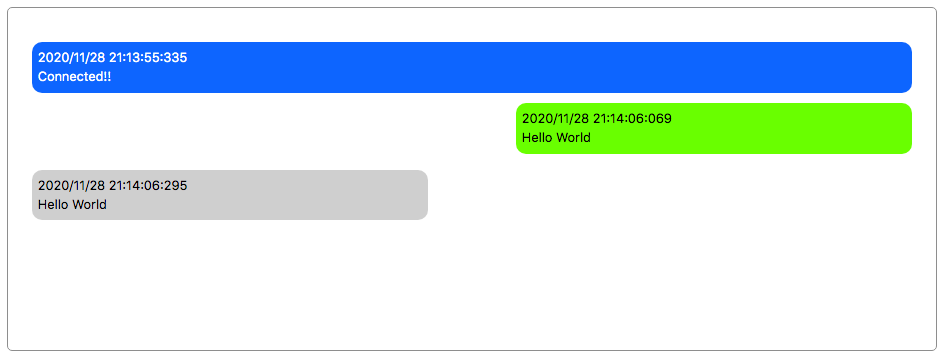
messagesにはWebSocketサーバーと送受信した情報が入っている。これをv-forを使ってレンダリングしていく。{{ message.date }}はメッセージを送受信した時刻が入っている。{{ message.body }}は送受信したメッセージそのものが入っている。:class="{ 'sent-message': message.from === 'client', ... }"の部分ではmessage送信者(message.from)に応じて動的にクラスを切り替えている。:class=...はv-binad:class=...の省略系となっている。
送信したメッセージ、受信したメッセージ、それ以外のメッセージで文字の色、背景色、配置を変えている。
.sent-message { background: #66ff00; color: black; margin-left: 55%; } .received-message { background: #d8d8d8; color: black; } .system-message { background: #007bff; color: white; width: 100%; margin: 10px auto; }
メッセージ送受信後に自動でスクロール実装部分
<section ref="messageArea" class="message-area"> ...
ref="messageArea"はVueで直接DOM操作するときに使うものらしい(getElementByIdのようなもの)。これを使ってメッセージ送受信後に自動でスクロールするように制御している。
Vue.nextTick(() => { let messageArea = this.$refs.messageArea; messageArea.scrollTop = messageArea.scrollHeight; })
Vue.nextTickはDOMの更新後に実行される関数。DOM更新後にscrollTopを更新していて最新のmessageが画面に表示されるようにしてる。
WebSocketサーバー接続部分
WebSocketサーバーと接続する部分。

<form> <div class="form-group"> <label for="serverURL">URL</label> <input @keydown.enter.prevent="connect" v-model="url" id="serverURL" type="text" class="form-control" placeholder="wss://..."></input> </div> <div> <button @click="connect" id="connectBtn" type="button" class="btn btn-primary">Connect</button> <button @click="disconnect" id="disconnectBtn" type="button" class="btn btn-secondary">Disconnect</button> </div> </form>
- WebSocketサーバーのURLを入力するinputフォームでEnterキーを押した時に実行される関数は
@keydown.enter.prevent="..."で指定している。keydown.enterはEnterキー押下時のイベントを表している。.preventはevent.preventDefault()と同じようにデフォルト動作を抑制している。
- inputフォームに入力されたURLは
v-model="url"を使ってurlという名前の変数に代入している。 - ボタンが押されたときに実行される関数は
@click="..."で指定している。これはv-on:click="..."の省略系となっている。
接続ボタン押下時のロジック
・ ・ this.conn = new WebSocket(this.url) this.conn.onopen = (event) => { this.onOpenListener(`Connected: ${this.url}`) } this.conn.onclose = (event) => { this.onCloseListener(`Disconnected: ${this.url} (code:${event.code} reason:${event.reason})`) } this.conn.onerror = (event) => { console.error("WebSocket error observed:", event); this.onErrorListener(`Error: ${this.url}`); } this.conn.onmessage = (msg) => { this.onMessageListener(msg.data) } ・ ・
this.urlはv-modelによってinputフォームと紐付けされた変数。- event.codeにはWebSocketのStatus Codeが入っている。
Status Code定義 tools.ietf.org
画面更新時にVueのテンプレートが表示される問題
画面を再読み込みしたりすると{{ message.date }}や{{ message.body }}が一瞬画面に表示されてしまう。これを回避するためにv-cloakを使っている。
[v-cloak] {
display: none;
}
・
・
・
<div id="app" v-cloak>
<h1>WebSocket Client</h1>
公式ドキュメントによると、
このディレクティブは関連付けられた Vue インスタンスのコンパイルが終了するまでの間残存します。[v-cloak] { display: none } のような CSS のルールと組み合わせて、このディレクティブは Vue インスタンス が用意されるまでの間、コンパイルされていない Mustache バインディングを隠すのに使うことができます。
とのこと。

















